01 · 2025 · Product Experience Mgmt (PXM) · AI
Salsify · An AI copilot for Kroger product content quality.
I led the design of Angie, an AI copilot inside Salsify that reviews retailer products against Kroger’s quality and style standards. The strategic call was deciding when the AI auto-fixes, when it surfaces for human judgment, and when it stays out entirely. I drew that line around consequence reversibility. Angie shipped in 2025 and now runs across product content published to Kroger through Salsify.
- 93%
- drop in manual review load
- Solo
- Design lead
- 16 mo
- May 2024 → Aug 2025
- Featured
- On Salsify’s blog
- Role
- Senior Product Designer · Solo design lead
- Team
- 1 PM · 1 EM · Engineering
- Tags
- AI copilot · Featured · Enterprise SaaS
Salsify's customers, large retailers and CPG brands, publish their product content to retailer catalogues like Kroger. When that content doesn't meet Kroger's standards, it gets rejected, buried in search, or flagged for manual review. The pre-Angie process was a chokepoint: someone had to triage Kroger's feedback and pass it back to retailers, often with days of latency. I led the design of Angie, an AI copilot inside Salsify's Feedback Status Report. Angie auto-fixes what's reversible, surfaces what needs human judgment, and stays out of the way of what's regulated. The strategic call I made was where to draw those lines: around consequence reversibility.
01. The brief
Manual review was the chokepoint, not the surface.
Kroger has detailed quality and style standards for the products that appear on its digital shelf. Naming conventions, claim restrictions, attribute requirements, formatting rules, prohibited language. The standards exist for good reason: they make the catalogue searchable and the brand consistent across thousands of categories. They're also extensive enough that retailers regularly publish content that violates them, often by mistake.
Pre-Angie, when a violation was caught, the path was painful. Kroger's QA system flagged the issue, Salsify staff triaged it, the feedback travelled back to the retailer through customer support, the retailer made the fix, and the product republished. Each round-trip was hours to days of latency. For high-volume retailers pushing thousands of SKUs, that latency compounded into real revenue loss. Products mis-listed, buried, or rejected at scale.
The brief I was given asked for "an AI assistant in the publish flow." The team was imagining a chat copilot that could help retailers draft better content. Possible. Useful. But on day three of discovery, when I sat down with the customer-success team and read three months of Kroger feedback tickets, the pattern was hard to miss: most of what humans were doing wasn't drafting at all. It was triage. Most feedback items were repetitive, mechanical, and obvious: sentence-case violations, extra spaces, missing required attributes, exaggerated language. The reviewers were doing low-judgment work, slowly, at scale.
02. Constraints
What shaped the work.
Four constraints shaped the design and ruled out otherwise-tempting options.
- Salsify's existing Feedback Status Report screen was already a load-bearing surface in customer workflows. I couldn't redesign the surrounding UI; Angie had to slot into a familiar surface, not replace it.
- Kroger's style guide is detailed and enforceable. The AI had to reflect it accurately or it would lose customer trust on the second use. Approximate AI doesn't pass enterprise procurement.
- Auto-fix has stakes. If the AI auto-fixes a brand claim incorrectly, even one in a thousand, it puts the retailer's reputation at risk, and Salsify's by extension. The line between "fix" and "suggest" couldn't be drawn by feature; it had to be drawn by consequence.
- Retailers vary widely in technical fluency. Some users are enterprise commerce teams with merchandising-ops experience; others are small CPG teams new to the platform. The feedback UI had to make sense to both without dumbing down for either.
“The brief asked for an AI assistant. The strategic call was deciding when to auto-fix and when to ask.”
03. The decision
Drawing the line between fix and ask.
The biggest call I made on this engagement was the rule for when Angie should auto-fix versus when it should surface feedback for a human to approve. The team's instinct, especially engineering's, was to lean toward auto-fix wherever the model was confident. The model is confident a lot. Auto-fix is engineering-tempting because it's measurable: lower review queue, faster throughput, cleaner dashboards.
I held the line on a different rule, drawn around consequence reversibility:
Reversible, low-stakes: Angie auto-fixes
Sentence-case violations, extra whitespace, obvious typos, formatting issues, attribute normalisation. These are mechanical, the right answer is unambiguous, and if Angie ever does get one wrong, the retailer can revert with a click. Auto-fix here is a gift, not a risk. Every auto-fix is logged in an audit trail the retailer can inspect.
Judgment-laden. Angie suggests, the retailer approves
Claim accuracy, brand voice, attribute mapping where the right value is contextual, anywhere two equally-plausible options exist. Angie surfaces the issue, proposes a fix, and waits for human acceptance. The retailer reads "Sentence case issue" and a suggested rewrite, and clicks "Accept and resolve" or "Try again." Friction is the feature here. It preserves the retailer's authorship.
Irreversible or regulated. Angie warns, never touches
Legal claims, regulatory language, anything that could create exposure if mis-handled. Angie flags it as a warning, explains what it sees, and stays out of the way. Auto-fixing here would be a category mistake.
The reversibility rule replaced what had been an ad-hoc, feature-by-feature engineering decision. I wrote it down in week three as a one-page principles doc, signed by design and engineering, and the team referenced it for every subsequent feature. Holding the line required arguing it weekly for the first month , auto-fix is easy to want and hard to defend against, especially when the model is performing well in testing. By month two the principle had earned itself.
04. How I led
Working with the team.
Solo design lead, working with the PM, the EM, and engineering. No other designers on the project, which meant the operating pattern mattered.
Mapped every Kroger feedback type with PM and EM in week one.
Three days, one whiteboard, every category of feedback Kroger's QA system emitted. Then we classified each by reversibility. Together. The shared classification became the spine of the feature, the engineering build plan, and the design principles doc. Doing this with the team rather than presenting it later was the most leverage I had on the engagement.
Co-designed the reasoning UI with engineering.
Every feedback item shows what Angie saw, what it suggested, and (when relevant) what it auto-fixed and why. The format-of-the-explanation was a design decision; the structure-of-the-data was an engineering decision. We negotiated both at the same time so the surface and the API matched without translation work.
Wrote Angie's voice as a separate artefact.
The AI's voice has to be specific, not chatty. "Sentence case issue" reads as a senior teammate; "Hmm, looks like there might be an inconsistency" reads as a chatbot. I wrote a short voice-and-tone doc with patterns for error labels, suggestion descriptions, welcome states, and limits-of-the-AI states. The voice doc is what kept the surface from drifting toward generic AI-assistant register.
Designed the limits states explicitly.
Most AI surfaces ship with happy-path interactions and silently break when a user asks something outside the AI's remit. I designed Angie's "I can't do that" states first. What Angie says when a retailer asks for things it shouldn't auto-fix, what it does when its confidence is low, what it surfaces when it doesn't know. These states do as much trust-building work as the success states.
05. AI-augmented practice
AI-augmented from the brief on.
The work moved as fast as it did because the practice around it was AI-augmented. Specific tools, used deliberately, each tied to a measurable saving in time or sharpening of judgment.
ChatGPT did the heavy lifting on triaging Kroger feedback at volume. What used to take an afternoon of pattern-reading became a half-hour with a model surfacing what mattered, freeing the human read for the judgment-required cases the AI couldn't sort.
NotebookLM held three months of customer-success tickets, vendor docs, and internal research notes in one queryable corpus. The reframe (manual review IS the chokepoint, not the publish surface) came out of one of those query sessions.
Cursor was the prototyping environment. Real-data prototypes in hours instead of days, with engineering reading the same code I was. The audit-log surface was a Cursor prototype before it was a Figma file.
Dovetail held the user research. Quotes tagged, themes surfaced, snippets shared with the team without anyone needing to watch the full recording.
Mixpanel and LogRocket ran side by side on the live surface. Behavioural data and session replay together meant every design decision had two kinds of evidence backing it.
The tools didn't replace judgment. They cleared the runway for it.
06. What we shipped
The product, in detail.
Angie shipped in 2025 and is live in Salsify today. The summary below walks through the surfaces in the order a retailer encounters them.
The Feedback Status Report. Angie inside the existing surface
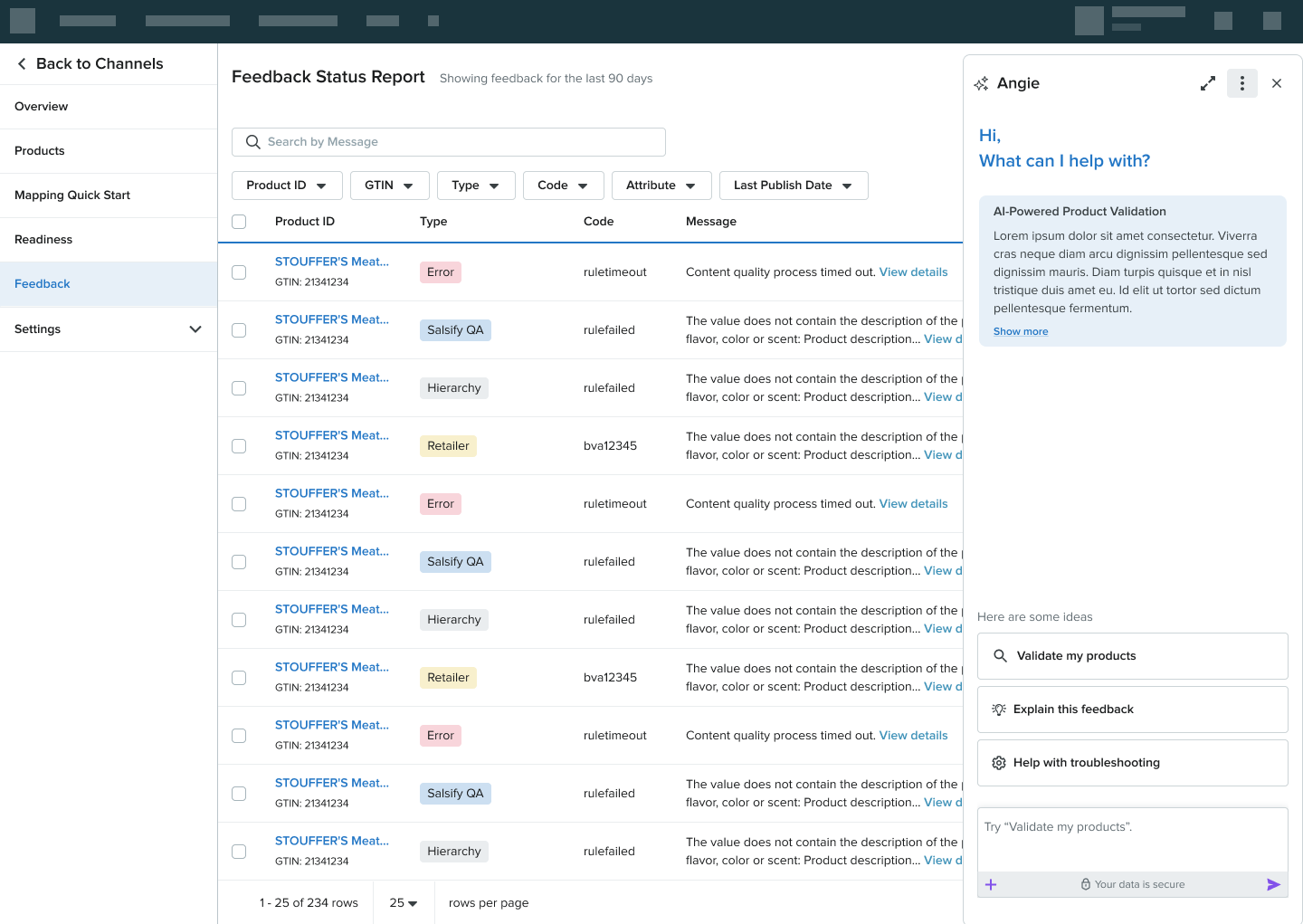
The Feedback Status Report is where retailers already triage Kroger's feedback. Angie lives as a panel that opens to the right of the report, contextualised to whatever feedback row the retailer is on. The retailer doesn't switch tools or tabs; the AI is in-context with whatever is already in front of them. Feedback is categorised across four types. Salsify QA, Hierarchy, Retailer, and Error. Each with a distinct visual treatment so retailers can triage at a glance.
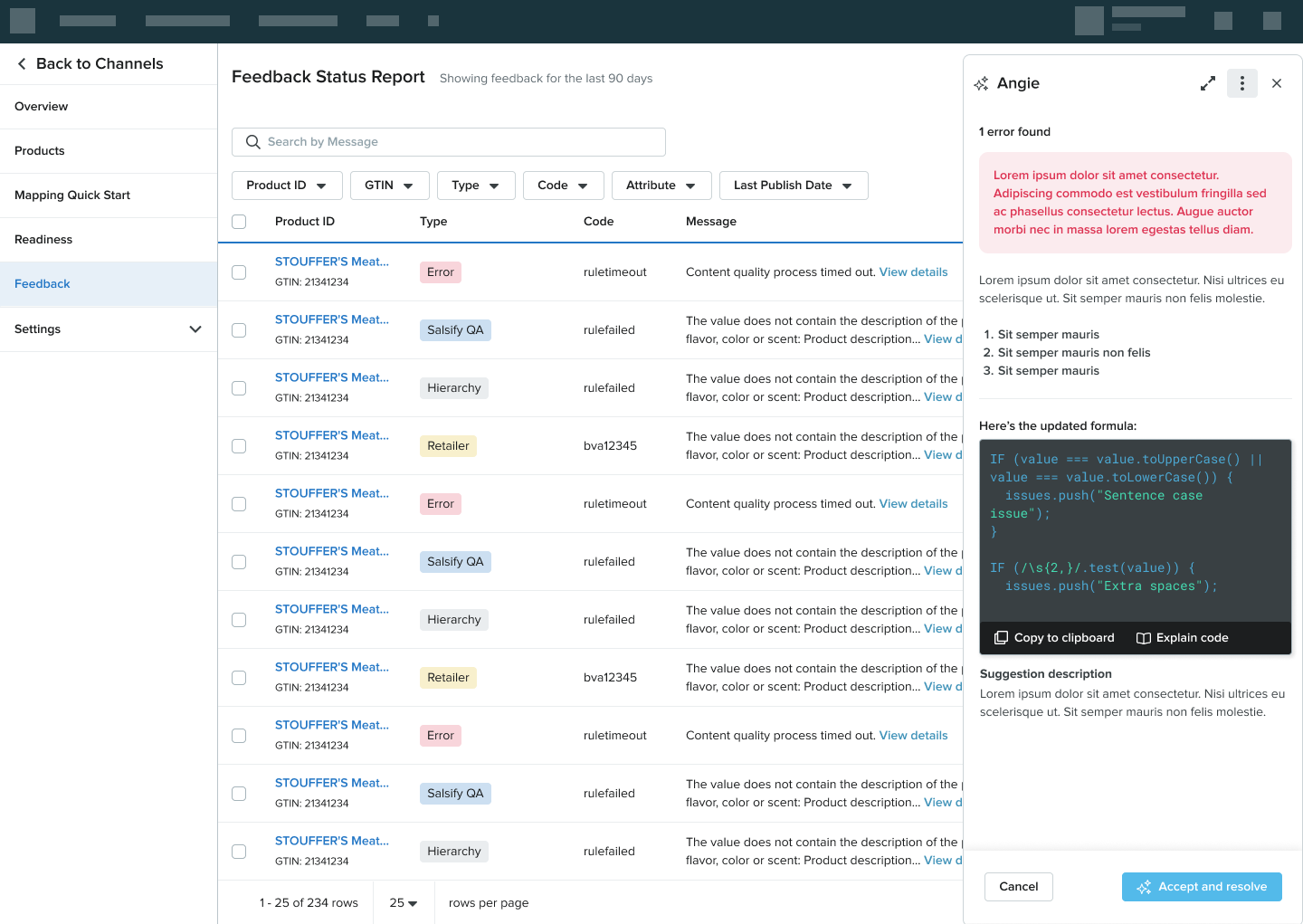
Per-error context with reasoning
When Angie opens against a specific error, the panel shows what was wrong, why, and either the auto-fix that was applied (with a "view audit trail" affordance) or the suggested fix the retailer can review. For complex errors, Angie shows the actual rule logic. Including formula snippets that engineering can copy and explain. So retailers can build mental models, not just resolve tickets. "Accept and resolve" and "Try again" controls anchor the bottom of the panel.
Welcome state with structured starting points
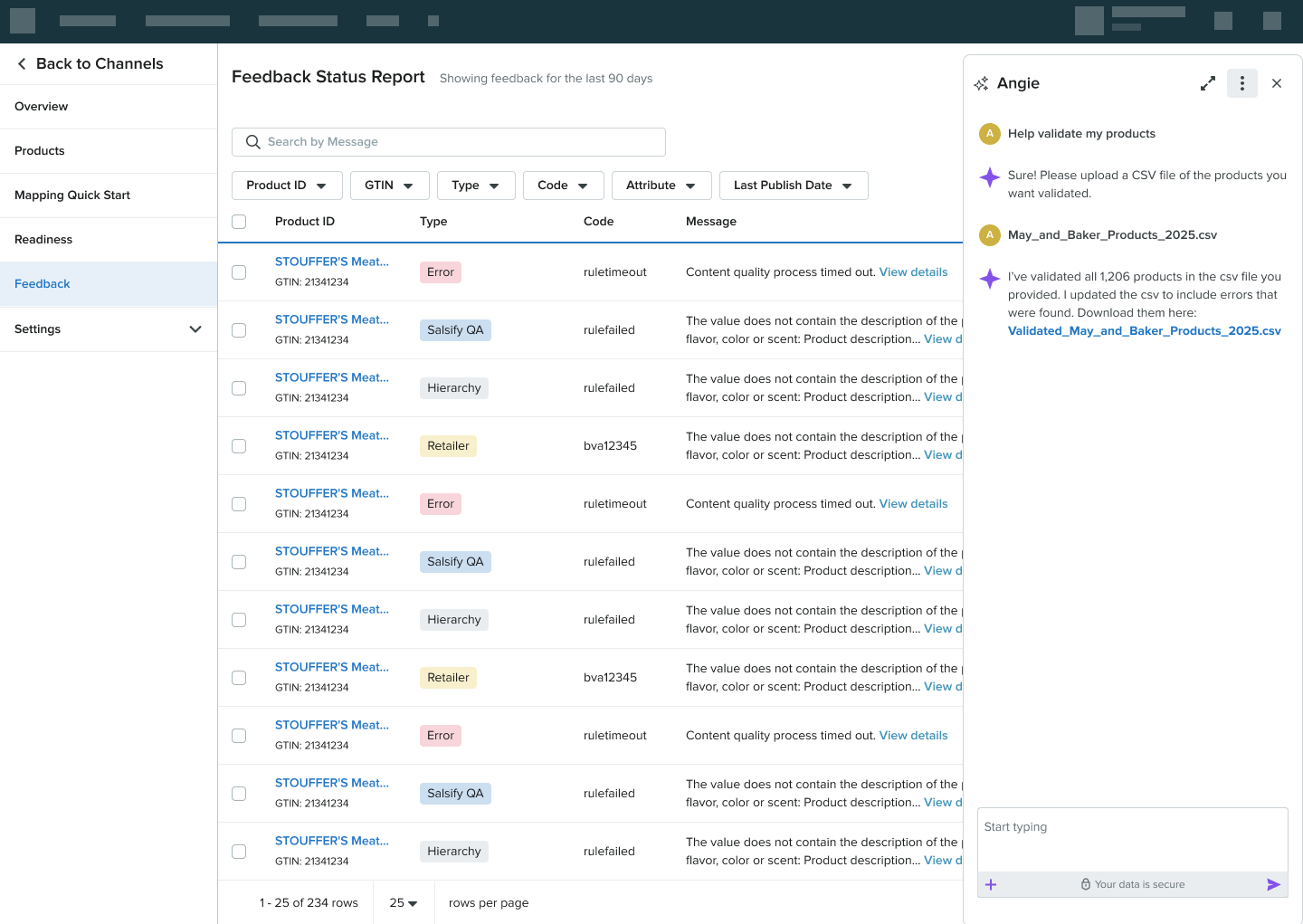
Most users won't type a prompt the first time they meet an AI assistant. Instead of the open prompt-box that pretends otherwise, Angie's welcome state offers three structured starting points. "Validate my products," "Explain this feedback," "Help with troubleshooting". That map directly to the work retailers came to do. Open-ended typing remains available; it's not the default invitation.
Bulk validation via CSV
For high-volume retailers, single-product validation isn't enough. Angie can ingest a CSV of products, validate every row against Kroger's standards, and return an annotated CSV with every issue flagged in-line. The version a retailer receives back is the same shape as the file they sent. No re-mapping required. Roughly 1,200 products per file is the comfortable working size we tested against.
Audit log
Every auto-fix is logged with the original value, the fixed value, the rule that triggered the fix, and the timestamp. Retailers can inspect any auto-fix and revert it. The audit log is what made the auto-fix tier defensible. It's the safety net that lets the team be aggressive on reversible items without exposing customers to risk.
Outcome
Better Kroger compliance, better visibility on the digital shelf, and meaningfully reduced manual review load.
Angie now reviews retailer products published to Kroger through Salsify. The directional outcomes the team has tracked: retailers ship more compliant content on the first pass, more products get accepted into the digital shelf without re-publish cycles, and the manual review queue is no longer the bottleneck it was. The work was significant enough that Salsify referenced it externally as part of their broader story on product-content quality with Kroger and Grainger.
The deeper outcome is the principle the work surfaced. The reversibility-based rule for AI auto-fix is now part of how the team thinks about every subsequent AI feature in the platform. It travels.
Reflection
The reversibility rule was the right call but the team initially pushed back. Auto-fix is engineering-tempting because it's measurable; "ship to a human queue for review" looks like a regression in throughput dashboards. Holding the line meant arguing every week for the first month, in a one-designer-against-the-room dynamic that's not a great way to operate. Next time I'd write the principles doc in week one, not week three, and have a senior engineer co-author it. Once the rule is countersigned, the conversation isn't replayed feature-by-feature. The work is just applying the rule rather than re-deriving it.